Road Marker Reconstruct
Computer Vision final project
3D Reconstruction from Road Marker Feature Points
In pursuit of developing an autonomous vehicle, we explored a visual-based localization approach that utilizes input from four cameras capturing different views. The primary objective of this project was to reconstruct a 3D point cloud based on road marker feature points extracted from the video input.
The pipeline we designed for this task involved the following steps:
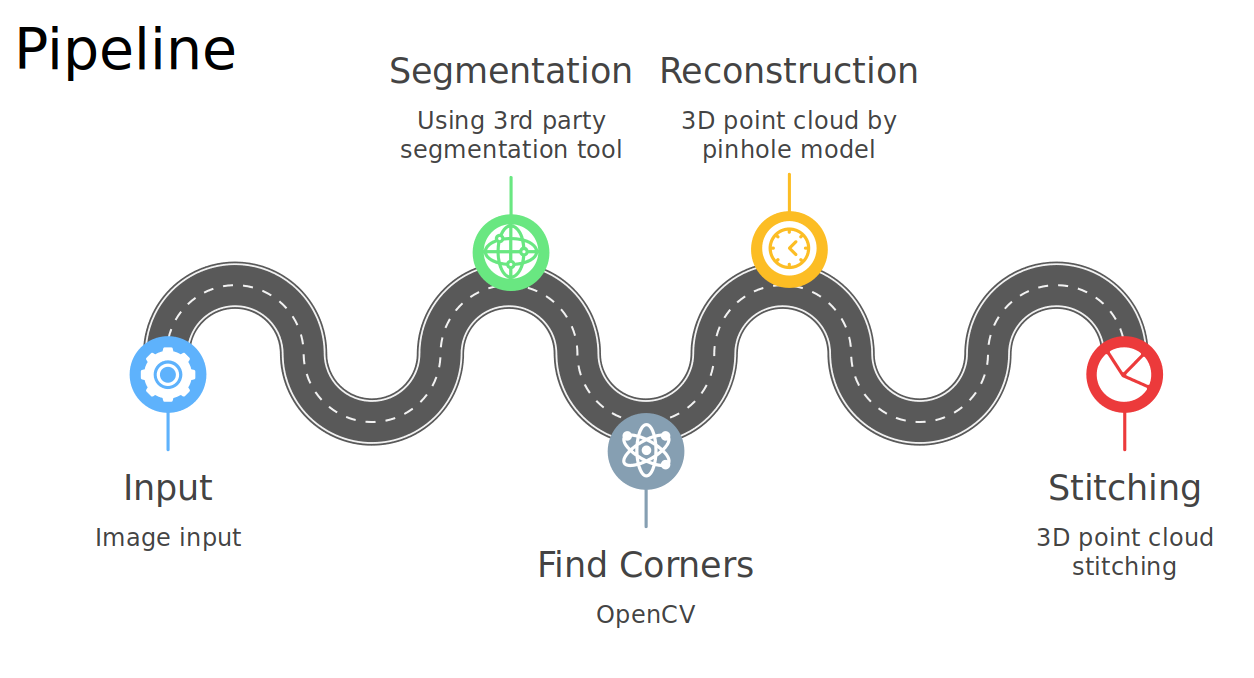
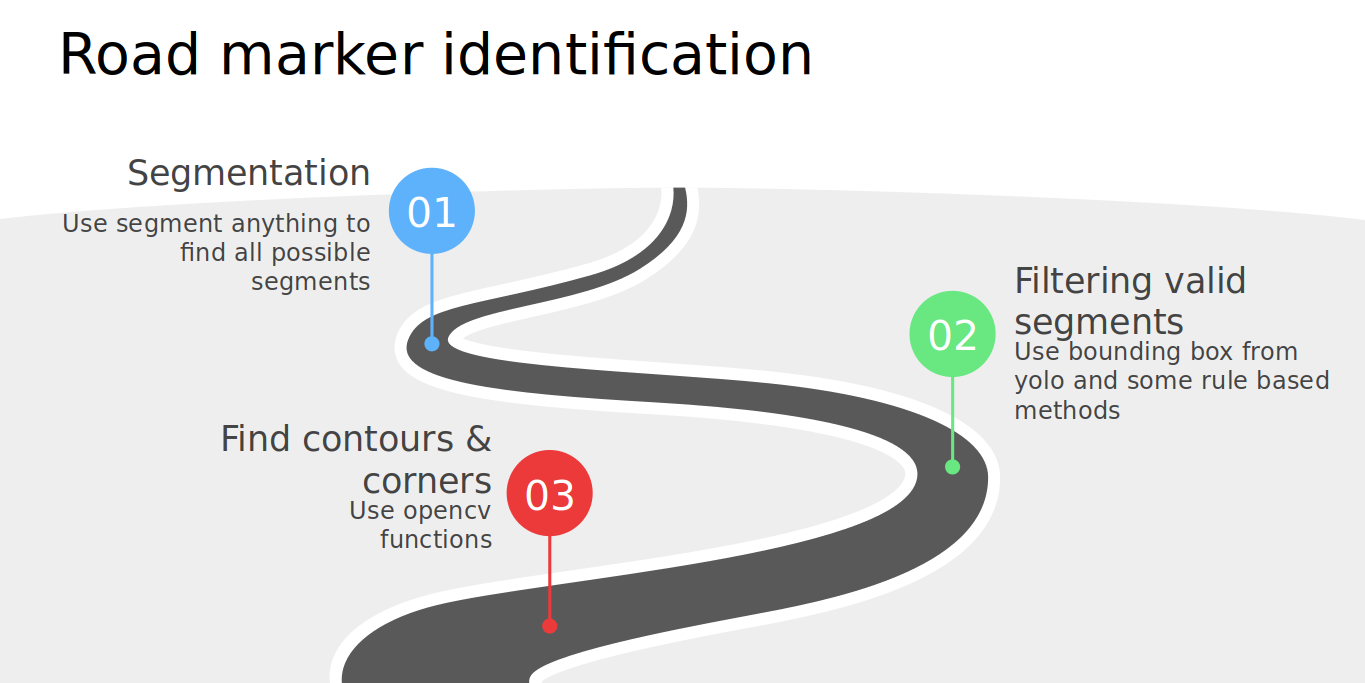
Video Input: The video input obtained from the four cameras (with time stamp) Image Preprocessing: From the video frames, we extracted road marker bounding boxes. Segmentation: Isolate the road marker corner points within the bounding boxes. Road Marker Corner Points: Find the detected corner points for reconstruction. 3D Reconstruction: Utilizing the pinhole model, we reconstructed the 3D representation of the road markers. Road Marker 3D Point Cloud: We concat pointcloud of 4 consecutive frames to get denser pointcloud.
This project was undertaken as a team effort for our Computer Vision class, and I am proud to share that our team achieved an impressive 6th place out of 18 competing teams. This accomplishment speaks to our dedication, collaborative spirit, and the effectiveness of our approach in tackling this complex challenge. The experience gained from this project has further strengthened our skills in computer vision and paved the way for future advancements in autonomous vehicle technologies.
| Video 1 | Video 2 |
|---|---|
 |  |
| Test Video 1 | Test Video 2 |
|---|---|
 |  |